Caucus is an 'application' that is installed on a Unix server or "host". This includes any flavor of Unix, including Linux, Solaris, MacOS X, BSD, HP-UX, and AIX. (It does not run on Windows servers -- but it doesn't care what kind of a computer or operating system the end users have.) People use Caucus through the web browser on their PC, connected over the Internet (or intranet) to the host. Caucus supports all modern browsers on all computers -- whether it's IE (Internet Explorer) 6 or 7, Firefox, Netscape, or Safari 3, on Windows, Macintosh, or Unix. When a person is using Caucus, their browser "talks to" software called the "web server" that is installed on the host. (Caucus works with most web servers, although Apache is the most common.) The web server in turn "talks" directly to the Caucus application, which actually generates the information that you see in your browser window. This architecture scales extremely well: for example, one university supports 10,000 total users (with a typical peak of 200 simultaneous users) on a desktop PC with 2GB of RAM, with no degradation of response time. The Caucus application may be installed multiple times on a single host, and each Caucus site is treated as a completely independent "virtual" host. Inside Caucus
Caucus itself consists of three layers:
- Each Caucus page that you see displayed in your browser is actually the output of what is called a "CML" (Caucus Markup Language) file. CML is a language like PHP or JSP or ASP, that describes what kind of data goes where on the page. Each page has its own CML file.
- The CML files are interpreted (evaluated) by a program called "swebs". Swebs combines the layout information in the CML files with the relevant data (such as the text of items or responses), and translates it all into the ordinary HTML text that your browser understands. (Swebs itself is written in another language, called 'C', that is included with all flavors of Unix.)
- Finally, swebs reads and writes the data from the hard disk on the host. The data is stored in MySQL, a sophisticated open source relational database.
Here's a much more detailed description of how all of the above happens. It will primarily be of interest to system administrators or software developers.
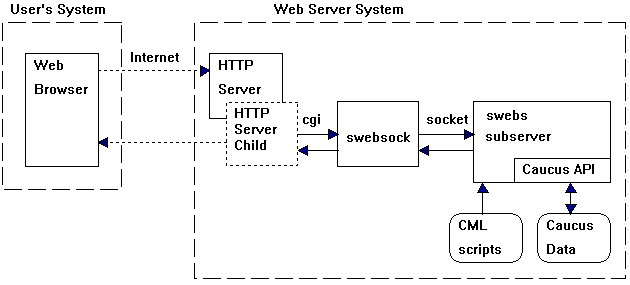
- When a person "logs in" to Caucus, their browser connects through the web (HTTP) server to an (always running) "daemon" process called "swebd".
- Swebd creates a new process running the swebs program, and assigns (dedicates) it to that person. All further communication happens to that swebs process.
- As shown in the diagram below, each time the user clicks on a link "in" Caucus, their browser sends a request across the net to the HTTP server (or server child process or thread). That in turn runs a very lightweight process called swebsock, which connects to the dedicated swebs process for that person.
- The request is processed by swebs, which determines which CML page is needed, and interprets it. Swebs calls the Caucus API, which reads and writes data to disk as necessary. The resulting HTML text is sent back, through swebsock, through the HTTP process, back to the user's browser.
 For further details, see the
original Caucus Architecture description.
For further details, see the
original Caucus Architecture description.